PyTorch框架深度学习笔记05(CNN实现MNIST手写数字识别代码)
上一篇笔记中,简单阐述了卷积神经网络的算法特点与原理,并且以 LeCun 发布的 LeNet-5 网络架构为例,把 PyTorch 框架下实现的手写数字识别的神经网络的核心代码呈现出来。本篇笔记将会完整实现 MNIST 手写数字识别,并且详细标记各个模块的作用。
PyTorch 核心组件
PyTorch 文档
通过查阅文档或询问AI可以高效的获取自己所需的信息,善用文档可以帮助我们更快的学会想要学习的框架。
核心组件
上次的笔记中已经简单提到了PyTorch 中用于构建和训练神经网络的核心模块 torch.nn,以及其中容器类中的核心基类 nn.Module 基类。不过,仍有许多 PyTorch 中关键的方法我们没有提到,而这次将会围绕“CNN实现MNIST手写数字识别代码”这个主题将他们一一引出。
MNIST手写数字识别
Part1.第三方库
import torch
from torch import nn,optim
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
from torchinfo import summary
torch与torch.nn见上篇笔记。optim(Optimization):这是 PyTorch 的另一个核心组件,提供了大量的优化算法,用于更新神经网络的模型参数。torchvision:提供了图像的预处理工具,用于数据增强和标准化等。from torch.utils.data import DataLoader:将数据集分批次(Batch)加载,支持多进程加速和数据打乱(shuffle)。torchinfo:顾名思义,提供了模型的可视化方法。
Part2.设置 PyTorch 的计算设备
print(torch.cuda.is_available())
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.cuda.is_available():检测 GPU 是否可用。torch.device("cuda" if ... else "cpu"):自动选择最佳计算设备(优先 GPU)。
如果按照笔记正确配置安装过CUDA,这里会选择使用GPU进行数据运算,之后的代码中会出现使用 .to(device)进行的数据或模型迁移到GPU上,以加速模型的训练推理。
Part3.超参数的设置
class Config:
LearningRate = 1e-2
Epochs = 5
BatchSize = 64
Transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: x * 255)
])
#参数设置对象创建
config = Config()
- 学习率(Learning Rate):这是神经网络训练过程中一个非常重要的超参数,它控制了模型参数在梯度下降时的更新步长。
- 训练轮数(Epochs):整个训练集被完整训练的次数,如果轮次过少可能会导致训练不充分(欠拟合),但是轮次太多又可能会导致过拟合。对于复杂的模型训练,通常会采用验证集和早停策略来动态控制训练轮数。
- 批次大小(Batch Size):每次输入的样本数量。这里设置的64即为每次处理(前向传播和反向传播)64张图像文件。
Transform = transforms.Compose([...])
定义数据预处理,用于对输入数据(如图像)进行标准化和转换。
transforms.ToTensor()将 PIL 图像或 NumPy 数组转换为torch.Tensor,并自动缩放到[0, 1]范围。transforms.Lambda(lambda x: x * 255)通过 Lambda 函数将张量值从[0, 1]重新缩放到[0, 255]。
Part4.下载与加载MNIST数据集
train_dataset = datasets.MNIST(
root='', # 数据集存储路径(空字符串表示当前目录)
train=True, # 加载训练集(共 60,000 张图片)
download=True, # 如果本地不存在,自动下载
transform=config.Transform # 应用预处理(如转张量、归一化)
)
test_dataset = datasets.MNIST(root='',train=False,download=True,transform=config.Transform)
train_dataset_size = len(train_dataset)
test_dataset_size = len(test_dataset)
train_loader = DataLoader(
dataset=train_dataset, # 指定训练集
batch_size=config.BatchSize, # 批次大小(如 64)
shuffle=True, # 打乱数据顺序(防止模型记忆顺序)
drop_last=True # 丢弃最后不足一个批次的数据
)
test_loader = DataLoader(dataset=test_dataset,batch_size=config.BatchSize,shuffle=True,drop_last=True)
这一部分已经在代码注释中详细标注。
Part5.定义 LeNet-5 CNN网络架构
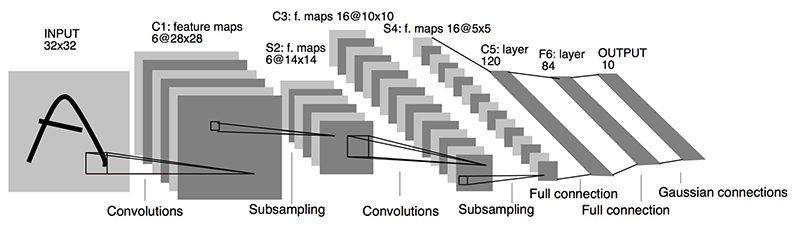
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0), # [1,28,28] -> [6,24,24]
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # [6,24,24] -> [6,12,12]
nn.Conv2d(in_channels=6, out_channels=28, kernel_size=5, stride=1, padding=0), # [6,12,12] -> [28,8,8]
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2), # [28,8,8] -> [28,4,4]
nn.Flatten(), # 展平为28*4*4=448维向量
nn.Linear(in_features=28*4*4, out_features=120), # 修改输入维度为448
nn.ReLU(),
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self,x):
x = self.model(x)
return x
这一部分我们已经在上次笔记中简单介绍了作用,这里稍做补充。
1.关键组件 nn.Conv2d(二维卷积层)
提取图像的局部特征(如边缘、纹理等),通过卷积核(kernel)在输入数据上滑动计算。
- 输入:
(batch_size, in_channels, height, width) - 输出:
(batch_size, out_channels, new_height, new_width)
nn.Conv2d(
in_channels=1, # 输入通道数(MNIST是灰度图,通道数为1)
out_channels=6, # 输出通道数(即卷积核数量)
kernel_size=5, # 卷积核大小(5x5)
stride=1, # 滑动步长(默认为1)
padding=0 # 边缘填充像素数(0表示不填充)
)
对于卷积运算输出大小,我们使用如下公式
2.有关最大池化层的知识已经在上篇笔记中详细讲述。
3.定义向前传播函数。
def forward(self,x):
x = self.model(x)
return x
定义了前向传播函数,输入的数据会通过 self.model = nn.Sequential() 进行传播。
Part6.神经网络模型对象创建与结构输出
net = Net()
net = net.to(device)
print(summary(net))
这里我们尝试打印出模型结构
=================================================================
Layer (type:depth-idx) Param #
=================================================================
Net --
├─Sequential: 1-1 --
│ └─Conv2d: 2-1 156
│ └─ReLU: 2-2 --
│ └─MaxPool2d: 2-3 --
│ └─Conv2d: 2-4 4,228
│ └─ReLU: 2-5 --
│ └─MaxPool2d: 2-6 --
│ └─Flatten: 2-7 --
│ └─Linear: 2-8 53,880
│ └─ReLU: 2-9 --
│ └─Linear: 2-10 10,164
│ └─ReLU: 2-11 --
│ └─Linear: 2-12 850
=================================================================
Total params: 69,278
Trainable params: 69,278
Non-trainable params: 0
=================================================================
参数量和模型结构十分清晰的输出了。
Part7.设置损失函数和优化模式
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
optim = optim.SGD(net.parameters(),config.LearningRate)
上一篇笔记中我们也提到了这三行代码,这里我们详细说明其功能。
-
交叉熵损失函数(Cross-Entropy Loss):适用于多分类任务,结合
Softmax和负对数似然损失,计算预测概率分布与真实标签的差异。Loss = -\sum_{i=1}^{C} y_{i}\log_{}{p_{i}} -
然后将损失函数移动到指定的计算设备(GPU 或 CPU),与模型和数据保持设备一致。
-
optim = optim.SGD(net.parameters(), config.LearningRate):定义随机梯度下降优化器(Stochastic Gradient Descent),用于更新模型参数。
Part8.模型训练与模型测试
def train():
for index,data in enumerate(train_loader):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
loss = loss_fn(outputs,labels)
optim.zero_grad()
loss.backward()
optim.step()
def test():
times = 0
for index,data in enumerate(test_loader):
times += 1
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
outputs = net(inputs)
accuracy = (outputs.argmax(axis=1) == labels).sum()
if times % 30 == 0:
print("Test accuracy:{0}".format(accuracy/len(labels)))
这里的代码作用已经在上一篇笔记有所提及,实际上我们定义好训练函数与测试函数之后,就可以开始循环训练和测试了。
for epoch in range(config.Epochs):
train()
if epoch % 5 == 0:
print("epoch {0}".format(epoch))
test()
print("Final accuracy")
test()
测试结果:
Final accuracy
Test accuracy:0.984375
Test accuracy:0.984375
Test accuracy:0.96875
Test accuracy:0.984375
Test accuracy:1.0